Research InterestsSheila Nirenberg, 3/13/2023
Research
Interests
People
Publications
Graduate Programs
Neuroscience
at Weill Cornell
Contact Information
Sheila Nirenberg
Department of Physiology
And Biophysics
Weill Medical College of
Cornell University
1300 York Avenue
New York, NY 10021
Office Phone: (212)746-6372
Lab phone:(212)746-5666
Fax: (212)746-8690
Email: shn2010@med.cornell.edu
Overview
The theme of our research is to advance basic understanding of computational neuroscience, and, in parallel, use what we learn to address practical problems that improve quality of life.
Our work is organized around three major goals:
- To understand the codes neurons use and the transformations they perform
- To use this understanding to build neuroprosthetics, brain machine interfaces, and robots
- To circle back and use our knowledge of the codes and transformations to advance other questions in systems neuroscience (e.g., population coding, how neurons collectively represent visual scenes, extract information, etc.)
So far, we’ve been focusing on these goals in the context of vision, but the ideas and tools generalize to other systems as well.
Background
The front end of every sensory system works essentially the same way: it has receptors that take in physical signals from the outside world, it has neural circuits that transform the signals, and, finally, it has output cells that send the transformed signals, in the form of action potentials, on to the brain.
In each case, what the system is doing is taking information from the outside world and transforming it into a code, a neural code that the brain can understand. So the question is: can we understand it? Can we understand at a fundamental level how the sensory world, which is made up of many patterns of light and sound and touches and tastes, can get transformed by a neural system into a code the brain can use?
Fig. 1 illustrates the problem specifically for the retina, the sensory system we’re working on. The figure shows an image (a baby’s face) entering the retina. When it enters, it stimulates the retina’s input cells, the photoreceptors. The photoreceptors then pass their signals through the retinal circuitry, which performs operations on them. What the circuitry does is extract information from the signals and convert the information into a code. The code is in the form of patterns of action potentials (spike trains) that are sent on to the brain.
So, in a nutshell, what the retina is doing is converting images into a code that the brain understands - and what we’re trying to do is decipher that code.
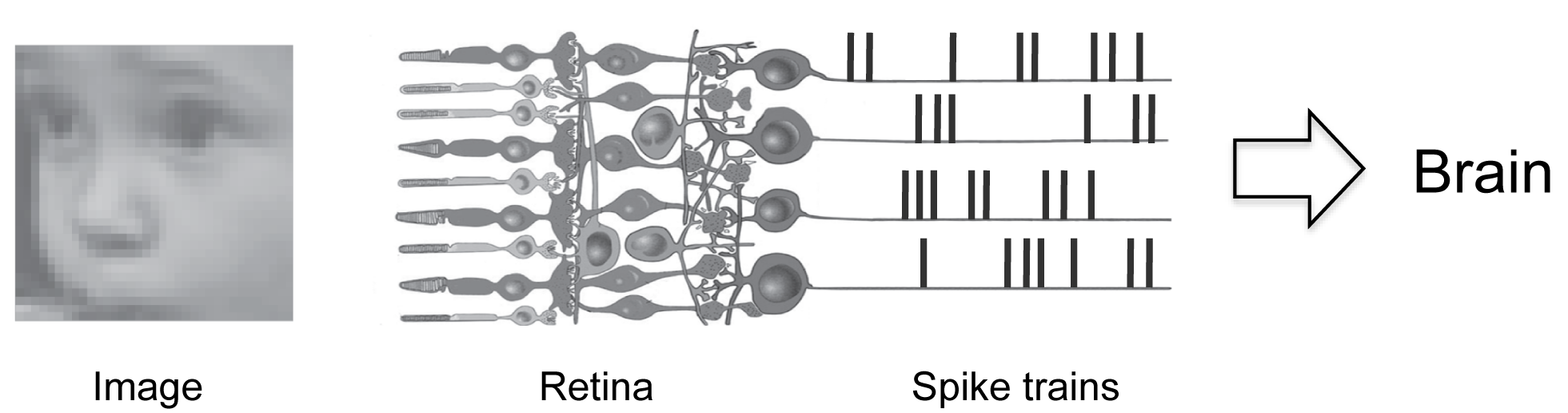
This is a pretty high dimensional problem. Just to give you a feel for it - while Fig. 1 shows just 4 spike trains, in reality, the retina is producing about a million, that is, there are about 1 million output cells in the retina, and each is producing a spike or no-spike every millisecond. So at every instant there are about 21,000,000 possible spike patterns to contend with (slightly less because there are correlations, but still an enormously large number). Even if we just consider the central retina, the area most important for vision, the number of possible spike patterns is about 210,000/ms (for 10,000 cells).
So, the key questions are:
- Can we reduce the dimensionality of the problem, so we can make it tractable? It turns out that the answer is yes, as we show in the next section.
- Given the dimension reduction, can we now find the transformation from visual input to retinal output (i.e., a mathematical model that will take us from images to patterns of action potentials)? Most significantly, can we develop the model such that it is effective on stimuli of essentially arbitrary complexity (stimuli of any kind, including faces, landscapes, people walking, etc.)? The answer to this is also yes, also, as we show in the next section.
- Finally, can we translate our understanding of the transformation into a prosthetic device for treating blindness? Yes, we are excited to say! As we show in the next section, we can make completely blind retinas, even ones with no photoreceptors at all, produce normal firing patterns to a broad range of stimuli. We’ve done this in mice and are translating it to a treatment for humans.
While a main focus right now is on developing the retinal prosthetic - so we can bring it forward to patients via Phase I/II clinical trials - we have several other projects going in the lab, in particular, the development of machine vision and robots, and the development of frameworks for studying how populations of neurons collectively solve problems, focusing on how they represent and extract visual information.
Making large scale problems tractable, using the retina as a model system
The retinal output cells (and neural populations in general) produce a large volume of data – tens of thousands of cells, each firing or not firing a spike every millisecond. How do we get a handle on this? How do we break the problem down so it’s tractable? The problem is similar to what was faced with DNA: 3 billion nucleotides – patterns of As, Gs, Cs, and Ts – what features in these long sequences matter? The unit of information (the codon) had to be discovered; the coding regions, the non-coding regions, etc., had to be unraveled.
Similar issues are relevant for spike trains. One of the most critical is determining whether the spike trains from individual cells can be treated as independent. Unlike the case with the genetic code, we have to deal with multiple sequences in parallel; different cells produce different spike trains, and the question is whether we can treat them as statistically independent (i.e., conditionally independent).
The reason the question is critical is because the answer affects the strategy we can take to deal with all the spike train possibilities. If the cells can be treated as independent, then we can use what are called “brute force” approaches to deal with them – that is we can obtain population probabilities by multiplying individual spike train probabilities (see refs. 1-3 for discussion)). If the cells can’t be treated as independent, then it becomes necessary to characterize the population activity using parametric models, which is nontrivial.
So we developed a strategy to address this. Briefly, we obtained an upper bound on the amount of information the retinal output cells can carry, then asked how much would be lost if we ignored the correlations in their spike trains (i.e., if we treated the cells as though they were independent). The results showed that very little was lost: for most pairs, almost nothing was lost, and even for the highly correlated pairs, the loss was <10% of the total stimulus information.
The reason so little is lost is that most of the information is carried in the independent spike patterns; the information in the correlations turns out to be redundant. The strategy and results, published in Nature and have been replicated now many times in many brain areas (somatosensory, motor, higher visual) using the same or similar methods, emphasizing the robustness of the result (4), and opening doors for studying population coding in many brain areas, too.
Finding the features of the spike trains that matter
The next issue focuses on the individual spike trains – what features of the spike trains matter? What is the coding unit? For example, is it the spike rate that carries information, or do the details of the spike trains contribute, too, e.g., the timing of the individual spikes, the correlations among the spikes, the latency-to-first-spike, etc.? This issue became increasingly important as more and more features of the spike trains were proposed to carry information, and, therefore, more and more neural codes were possible (5-12).Like many groups, we focused on this question, but we took a different approach (since our focus was on dimension reduction) (13). Instead of putting more codes on the table, we focused on taking them off, on reducing the number of possibilities. To address this, we set up a strategy for ruling codes out. The idea was to eliminate codes that aren’t viable (that can’t account for the animal’s behavior), so we could close in those that truly are.
Briefly, the strategy was to take a set of codes and measure each one’s upper bound performance, then compare it to the performance of the animal. The upper bound was obtained by measuring performance using the same number and distribution of cells the animal uses, the same amount of data the animal uses, and a decoding strategy that’s as good or better than the one the animal uses (i.e., optimal/Bayesian decoding). If the upper bound performance fell short of the animal’s performance, then the code could be ruled out, because this indicates very strongly that the animal can’t be using it.
We tested 3 widely-proposed codes (the spike count code, spike timing code, and temporal correlation code), and the results showed that the first two did, in fact, fall short, but the temporal correlation code emerged as a viable candidate code. While this doesn’t prove that it is the neural code, it’s sufficiently close to serve as the basis of models for neural computations (at least for vision), and for building neuro-prosthetics (13).
Finding the full transformation from visual input to retinal output
Given that we reduced the problem into a tractable range, we set out to find the transformation from visual input to retinal output, because this is the crucial step!To recap the transformation problem – the retina is continually presented with images (faces talking, cars driving by, obstacles that appear and disappear in our paths as we move, etc); the circuitry of the retina then transforms these images – it extracts information from them and converts the information into patterns of action potentials. The question is – can we capture this transformation?
We recently developed a mathematical model that can do this. The model builds on the principles of linear-nonlinear cascade models, but stands apart from other approaches in that it generalizes to stimuli of essentially arbitrary complexity, that is, it captures the transformation from visual input to retinal output for essentially any image in real time. (A complete description of the model is in ref. 14 and patent (ref. 15, p. 30-32).
Capturing this transformation has substantial impact. As we show in the next sections, it opens the door (it actually leads directly) to new treatments for blindness, to completely new capabilities for machine vision, and to a new array of tools for addressing questions in basic neuroscience.
Generating a retinal prosthetic capable of restoring normal or near-normal vision
The development of a retinal prosthetic has been a long-standing problem. There are 2 million people in the US and many more worldwide with advanced stage blindness, and while there are treatments being developed for early stage cases, for those with advanced stage disease, who are reaching the end of the line, there’s little that can be done (16,17). For these patients, their best hope right now is through prosthetic devices (16).
The problem is that current prosthetics don’t work that well. They’re still very limited in the vision they can provide. Patients can see, for example, spots of light and high contrast edges (16,18,19), but not very much more. Nothing close to normal vision has been possible.
Much of the effort to improve the devices has focused on increasing the resolution of their stimulators. Several groups have been advancing this, using both electrode and optogenetic approaches (20-27).
But there’s another critical problem, too: directing the stimulators to produce normal retinal output (output in the code the retina normally uses to communicate with the brain). With the model we can do this.
Using the mouse as a test case and optogenetic stimulation, we generated a prosthetic system that can produce normal output – this dramatically increased the system’s capabilities, well beyond what could be achieved by just increasing resolution. Most significantly, the results show that the combination of the neural code and high resolution stimulation is able to bring prosthetic capability up the level of normal or near-normal image representation (14,15).
Fig. 2 shows a block diagram of the prosthetic. It consists of two parts: what we refer to as the encoder and the transducer. The encoder mimics the transformations performed by the retina: it converts images as they enter the eye into the code used by the retina’s output cells, and the transducer then drives the output cells to fire according to the code.

(The encoder is the mathematical model described in the previous section but now implemented on a chip, and the transducer is a set of stimulators (e.g., electrodes or channelrhodopsin). For our first embodiment we used channelrhodopsin-2 (ChR2).) (A complete description of the device, the results, the strategy for translation to patients (including the code for primates) is provided in refs. 14, and 15.
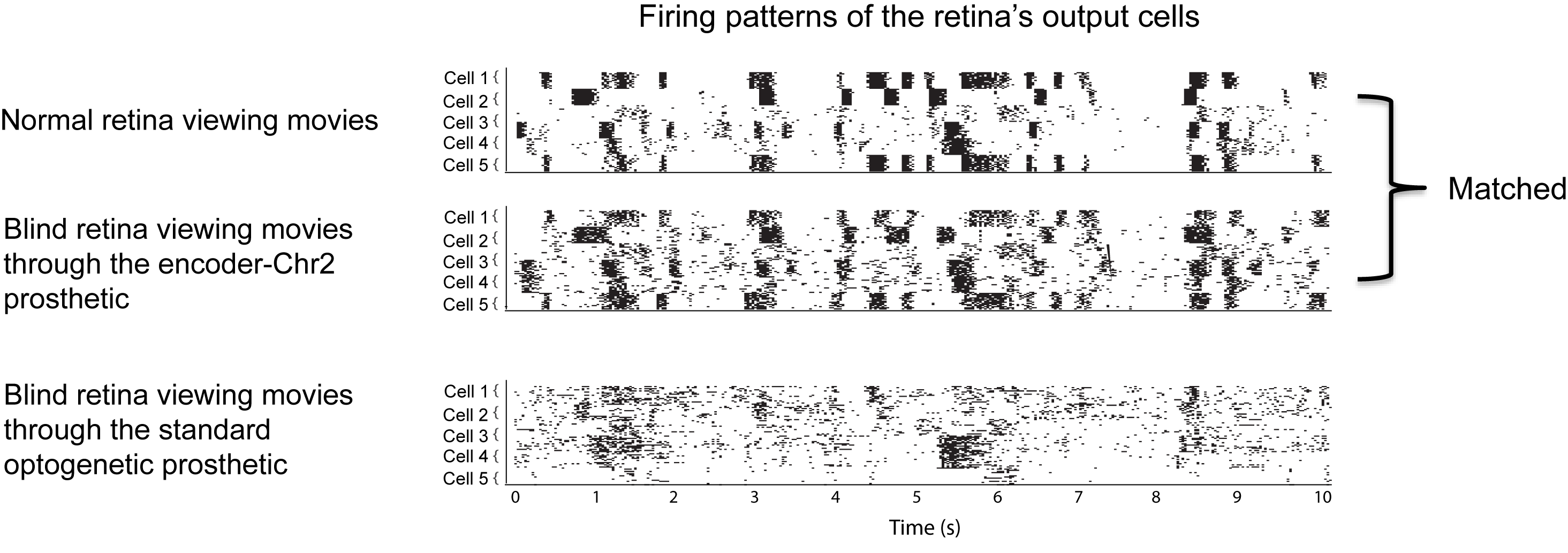
Figs. 3 and 4 show the effectiveness of the approach (using ChR2 as the transducer). We start with the effectiveness at the level of the retinal firing patterns (the firing patterns of the output cells, the ganglion cells) (Fig. 3). We presented movies of natural scenes, including landscapes, faces, children playing, etc., and recorded the resulting firing patterns from three groups of retinas: retinas from normal animals, retinas from blind animals that were viewing the movies though the encoder-ChR2 prosthetic, and retinas from blind animals that were viewing the movies though the standard optogenetic prosthetic (which has no encoder, just ChR2).
As shown in the figure, the firing patterns produced by the encoder-ChR2 prosthetic closely match those of the normal retina.
How important is this? What’s the potential impact on a patient’s ability to see?
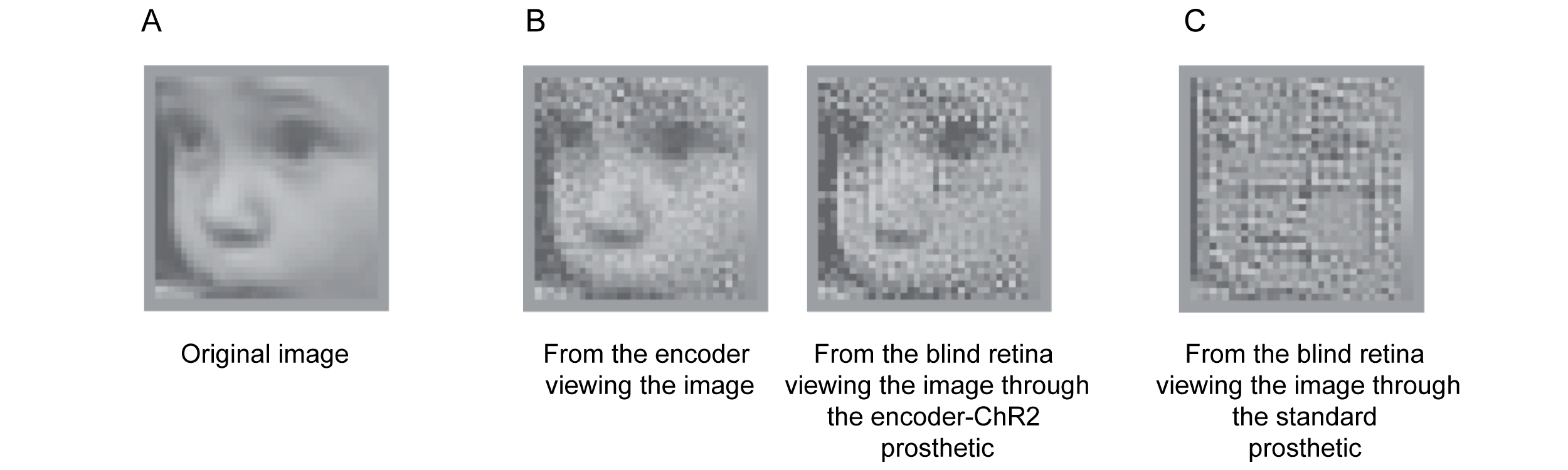
We tested this using three sets of experiments: reconstructions, confusion-matrices, and a behavioral assay (all shown in ref. 14), but because of the space constraint, we’re only able to show one here: the reconstructions (Fig. 4). We presented an image (a baby’s face) to two sets of blind retinas – those viewing it though the encoder-ChR2 prosthetic and those viewing it through the standard optogenetic prosthetic. We then recorded the responses and reconstructed the face from them (methods in Fig. 4 legend). As shown, incorporation of the retina’s code dramatically improves prosthetic capabilities. Not only is it possible to discern that the image is a baby’s face, but it’s possible to discern that it’s this particular baby.
Potential for Translation
We are currently using adeno-associated viral (AAV) vectors to deliver channelrhodopsins, as several clinical and preclinical trials have shown both safe and efficient delivery of genes with these vectors in ocular settings (37-41). In terms of driving the channelrhodopsin, we’ve built a device that contains a camera, the encoder and a stimulator (a miniDLP), and incorporated it into a pair of eye glasses (about the size of ski googles), so the patient can wear the device, and it can interact with the channelrhodopin in his or her eye.
One potential bottleneck for the development of this prosthetic for patients is the issue of targeting codes to specific ganglion cell classes. As is well known, the ganglion cell population contains several cell classes. This might raise the concern that, to produce quality vision, one would need to stimulate each class with its appropriate code. However, there’s strong evidence to suggest that this is not the case. Patients with Duchenne’s muscular dystrophy lack ON channel transmission, and, thus, see exclusively through OFF cells (42,43). These patients don’t report vision problems (42,43). They are actually unaware of the deficiency; it becomes apparent only through electrophysiological measures (i.e., ERGs (43). Thus, driving just a single class of cells with its code has the potential to produce substantial vision restoration [see ref 14, Nirenberg and Pandarinath (2012), Supp Info) for encoder performance for specific ganglion cell types: for mouse (Fig. S1) and for primate (Fig. S4), including ON and OFF midget and parasol classes (Fig. S4)].
Thus, although it is likely that there will be hurdles to overcome to bring this technology to patients, the major ones — a vector (AAV) for delivering channelrhodopsin to ganglion cells, an encoder/stimulator device to drive them, and the fact that targeting a single ganglion cell class by itself can bring substantial vision restoration — have already been addressed, substantially increasing the probability of success.
Our focus with this project now is heavily on translation to patients. In the last year we have moved forward on several fronts:
Building robots
A key aspect of our research is the interplay between biological and machine vision. As is well known, the visual world is extremely complex. Our brains are continuously flooded with visual signals, and yet they are rapidly parsed and utilized. A primary reason for this is the dimension reduction performed by the front end of the visual system. Millions of years of evolution have shaped the front end of the visual system into a powerful dimension reduction machine. It takes visual input, pulls out what we need to know and discards the rest. If this dimension reduction were harnessed, the capabilities of machine vision would be greatly increased.
We’ve recently done this. We developed an algorithm to perform, essentially, the same dimension reduction. Put in practical terms, what it does is collapse the staggering amount of information in the visual world into a tractable form. We’re now using this collapsed form to build robots and to increase capabilities for navigation, face recognition, and object recognition.
Other problems in basic science: building on what we’ve learned to understand population coding
A fundamental goal in visual neuroscience is to understand how information from the outside world is represented in the activity of populations of neurons. At every level of the visual system – from retina to cortex – visual information is arrayed across large populations of neurons. The populations are not uniform, but contain many different cell classes, with each class having its own visual response properties. Understanding the roles of the different cell classes and how they work together to collectively encode visual scenes has been a long-standing problem.
To address this we use a combined model/experiment approach. We start with the model, using it as a hypotheses-generating tool. We present it with images and obtain responses. We then decode the responses with and without specific cell classes included. In this way, we can ask: what stimulus features are lost when the responses of a cell class (or combination of classes) are not included? What role does that class play in representing visual scenes?
We evaluate the results two ways: first, qualitatively, using reconstructions (14,15,30), and then, quantitatively, by measuring performance on visual tasks (14,15,32,36). Given the hypotheses generated, we then go back and test them experimentally, as described in our previous work (14-16,32,36).
References
- Nirenberg, S. et al. (2001) Retinal ganglion cells act largely as independent encoders. Nature 411, 698-701.
- Nirenberg, S. and Latham, P.E. (2003) Decoding neuronal spike trains: how important are correlations? Proc. Natl. Acad. Sci. 100, 7348-7353.
- Dayan, P. and Abbot, L. F. (2001) Theoretical Neuroscience, pp. 36, 134, 363. MIT Press, Cambridge, MA.
- Averbeck, B.B. and Lee, D. (2004) Coding and transmission of information by neural ensembles. Trends in Neurosci. 27, 225-230.
- Oram, M. et al. (2002) The temporal resolution of neural codes: Does response latency have a unique role? Philos. Trans. R. Soc. Lond. Ser B 357, 987–1001.
- Victor, J.D. (1999) Temporal aspects of neural coding in the retina and lateral geniculate. Network 10, R1–66.
- Borst, A. and Theunissen, F. (1999) Information theory and neural coding. Nat. Neuro. 2, 947–957.
- Johnson, D.H. and Ray, W. (2004) Optimal stimulus coding by neural populations using rate codes. J. Comput. Neurosci. 16, 129–138.
- Theunissen, F. and Miller, J.P. (1995) Temporal encoding in nervous systems: A rigorous definition. J. Comput. Neurosci. 2, 149–162.
- Shadlen, M.N. and Newsome, W.T. (1994) Noise, neural codes and cortical organization. Curr. Opin. Neurobiol. 4, 569–579.
- MacLeod, K. et al. (1998) Who reads temporal information contained across synchronized and oscillatory spike trains? Nature 395, 693–698.
- Bialek, W. et al. (1991) Reading a neural code. Science 252, 1854–1857.
- Jacobs, A.L. et al. (2009) Ruling out and ruling in neural codes. Proc. Natl. Acad. Sci. 106, 5936-5941.
- Nirenberg, S. and Pandarinath, C. (2012) A retinal prosthetic with the capacity to restore normal vision. Proc. Natl. Acad. 109; 15012-15017.
- Nirenberg, S. et al. (2011) Retina prosthesis. International patent WO2011106783.
- Chader, G.J. et al. (2009) Artificial vision: needs, functioning, and testing of a retinal electronic prosthesis. Prog. Brain Res. 175, 317-332.
- Chopdar, A. et al. (2003) Age related macular degeneration. BMJ 326, 485-488
- Zrenner, E. et al. (2009) Subretinal microelectrode arrays allow blind retinitis pigmentosa patients to recognize letters and combine them to words. The IEEE 2nd Annual Conference in Biomedical Engineering and Informatics, pp. 1-4. IEEE.
- Nanduri, D. et al. (2008) Retinal prosthesis phosphene shape analysis. 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, pp. 1785-1788. IEEE.
- Loudin, J.D. et al. (2007) Optoelectronic retinal prosthesis: system design and performance. J. Neural. Eng. 4, S72-84.
- Sekirnjak, C. et al. (2008) High-resolution electrical stimulation of primate retina for epiretinal implant design. J. Neurosci. 28, 4446-4456.
- Bi, A. et al. (2006) Ectopic expression of a microbial-type rhodopsin restores visual responses in mice with photoreceptor degeneration. Neuron 50, 23-33.
- Lagali, P.S. et al. (2008) Light-activated channels targeted to ON bipolar cells restore visual function in retinal degeneration. Nat. Neurosci. 11, 667-675.
- Tomita, H. et al. (2009) Visual properties of transgenic rats harboring the channelrhodopsin-2 gene regulated by the thy-1.2 promoter. PLoS One 4, e7679.
- Thyagarajan, S. et al. (2010) Visual function in mice with photoreceptor degeneration and transgenic expression of channelrhodopsin 2 in ganglion cells. J. Neurosci. 30, 8745-8758.
- Greenberg, K.P. et al. (2011) Differential targeting of optical neuromodulators to ganglion cell soma and dendrites allows dynamic control of center-surround antagonism. Neuron 69, 713-720.
- Doroudchi, M.M. et al. (2011) Virally delivered Channelrhodopsin-2 Safely and Effectively Restores Visual Function in Multiple Mouse Models of Blindness. Molecular Therapy 19, 1220-1229.
- Grimm, C. et al. (2004) Constitutive overexpression of human erythropoietin protects the mouse retina against induced but not inherited retinal degeneration. J. Neurosci. 24, 5651-5658.
- Hackam, A.S. et al. (2004) Identification of gene expression changes associated with the progression of retinal degeneration in the rd1 mouse. Invest. Ophthalmol. Vis. Sci. 45, 2929-2942.
- Paninski, L. et al. (2007) Statistical models for neural encoding, decoding, and optimal stimulus design. Prog. Brain Res. 165, 493-507.
- Nirenberg, S. (2012) A retinal prosthetic with the capacity to produce normal vision, Dept of Defense, Vision Research Initiative DOD W81XWH-11-VRP-IIRA ERMS: # 11258009.
- Bomash, I. et al. (2012) A virtual retina: a tool for studying population coding, in press.
- LeCun, Y. et al. (2010) Convolutional Networks and Applications in Vision. Proc. International Symposium on Circuits and Systems (ISCAS'10), pp. 253-256. IEEE.
- Szarvas, M. et al. (2005) Pedestrian detection with convolutional neural networks. Proc. Intelligent Vehicles Symposium, pp. 224- 229. IEEE.
- Jackel, L. D. et al. (2006) The DARPA LAGR program: Goals, challenges, methodology, and phase I results. Journal of Field Robotics, 23, 945–973.
- Pandarinath, C. et al. (2010) Symmetry breakdown in the ON and OFF pathways of the retina at night: functional implications. J. Neurosci., 30, 10006-10014.
- Maguire AM, et al. (2008) Safety and efficacy of gene transfer for Leber’s congenital amaurosis. N Engl J Med, 358, 2240–2248.
- Hauswirth WW, et al. (2008) Treatment of leber congenital amaurosis due to RPE65 mutations by ocular subretinal injection of adeno-associated virus gene vector: short- term results of a phase I trial. Hum Gene Ther, 19, 979–990.
- Cideciyan AV, et al. (2009) Vision 1 year after gene therapy for Leber’s congenital amaurosis. N Engl J Med 361, 725–727.
- Simonelli F, et al. (2010) Gene therapy for Leber’s congenital amaurosis is safe and effective through 1.5 years after vector administration. Mol Ther 18, 643–650.
- Mancuso K, et al. (2009) Gene therapy for red-green colour blindness in adult primates. Nature 461, 784–787.
- Fitzgerald KM, Cibis GW, Giambrone SA, Harris DJ (1994) Retinal signal transmission in Duchenne muscular dystrophy: Evidence for dysfunction in the photoreceptor/depolarizing bipolar cell pathway. J Clin Invest 93, 2425–2430.
- Cibis GW, Fitzgerald KM (2001) The negative ERG is not synonymous with night-blindness. Trans Am Ophthalmol Soc 99, 171–175, discussion 175-178.
For information on neuroscience research in general in the tri-Institute community (Weill Cornell, Rockefeller University and Sloan Kettering), please see the following websites:
http://neuroscience.med.cornell.edu
http://www.rockefeller.edu/research/area_summary.php?id=3
http://www.mskcc.org/mskcc/html/8960.cfm